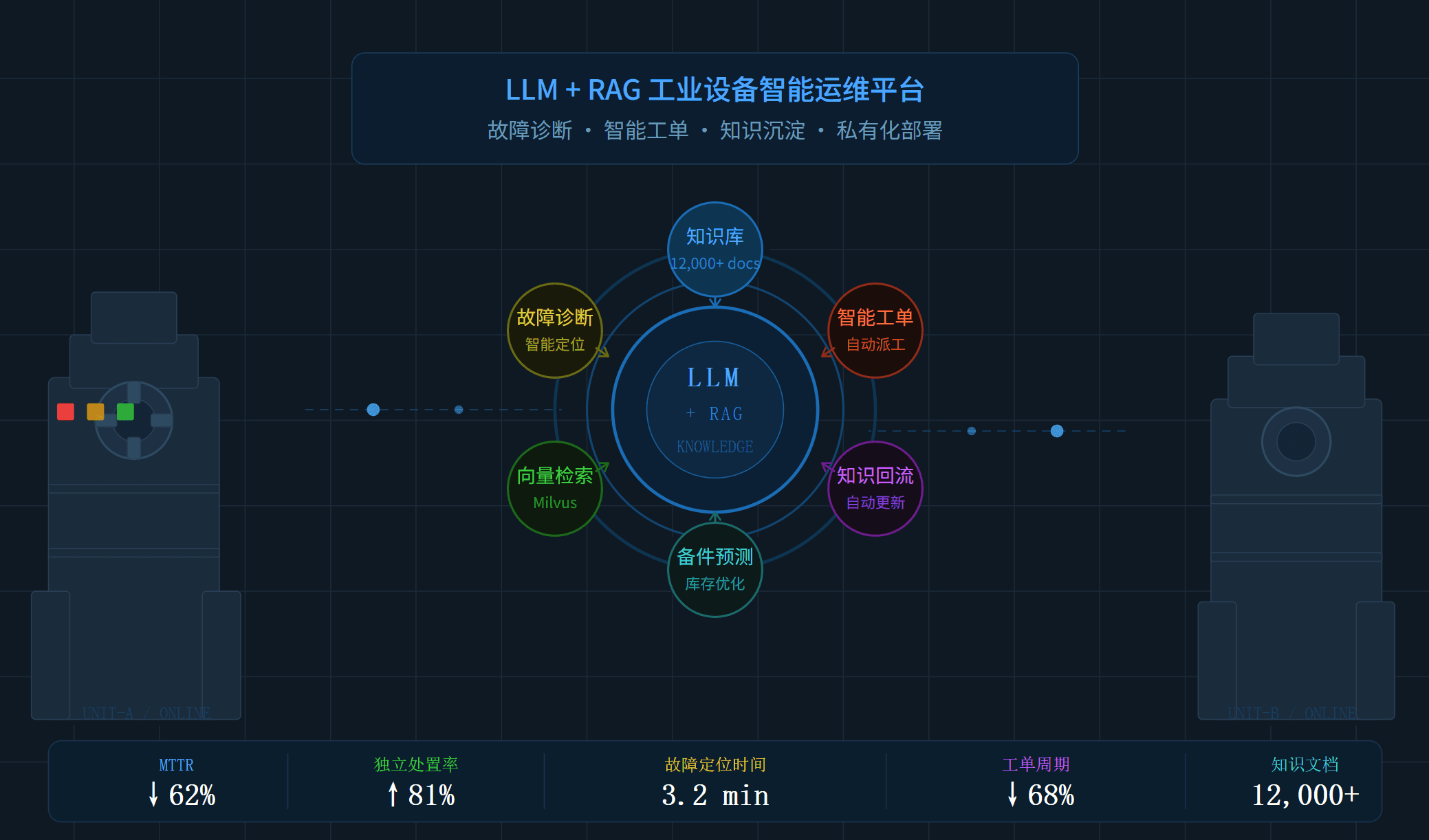
某重工智能科技有限公司拥有分布于全国多个基地的数万台工业设备,长期面临故障诊断依赖老师傅经验、维修知识难以传承、工单流转效率低下等痛点。我们为其构建了基于 LLM+RAG 的企业私有知识库平台,将二十余年的设备维修手册、故障案例与专家经验结构化入库,实现故障原因秒级智能定位、维修方案自动推荐及工单全生命周期智能管理,设备平均故障修复时长缩短 62%,一线技术员独立处置率提升至 81%。
客户背景
某重工智能科技有限公司成立于 2001 年,专注于大型矿山、冶金及港口装卸设备的制造与运维服务,在华东、华南、西南设有三大生产基地,管理设备超过 3.2 万台,一线运维技术员 1,400 余人。
随着公司规模扩张,设备运维面临三大核心挑战:
- 经验断层:核心技师平均年龄 52 岁,退休潮导致二十年积累的诊断经验面临流失风险;
- 知识孤岛:设备手册、故障报告、维修日志分散存储于纸质档案、本地硬盘和多套异构系统,无法有效检索;
- 响应迟缓:一线员工遇到复杂故障需逐级上报,平均等待专家介入时间超过 4 小时,严重影响生产连续性。
痛点分析
在项目启动阶段,我们对该公司运维体系进行了为期三周的深度调研,梳理出以下关键痛点:
1. 故障诊断严重依赖个人经验
传统诊断流程中,一线技术员需凭借自身经验或电话求助高级工程师。针对同一类设备的相似故障,不同技术员的处理方式差异悬殊,导致修复质量参差不齐。
2. 海量技术文档无法有效利用
公司积累了 12,000 余份设备手册、维修记录和故障案例,但全部以 PDF、Word 乃至纸质扫描件形式存在。面对具体故障,技术员平均需花费 40 分钟以上才能找到相关参考资料,且命中率极低。
3. 工单流转缺乏智能化支撑
现有工单系统仅支持手工填写和线性审批,无法根据故障类型自动匹配技能标签、推荐备件清单或预估工时,工单信息质量低,导致派工错误和二次返修频发。
解决方案
整体架构
我们设计了以「私有知识库」为核心的三层智能化架构,打通知识沉淀、故障诊断与工单管理三条主线。
%%{init: {'theme': 'dark', 'themeVariables': {'primaryColor': '#1A3A5C', 'primaryTextColor': '#A8D4F5', 'primaryBorderColor': '#2D6A9F', 'lineColor': '#4A9FD4', 'secondaryColor': '#0F2535', 'tertiaryColor': '#0A1E30', 'clusterBkg': '#0D2540', 'clusterBorder': '#1E5080', 'edgeLabelBackground': '#0A1E30', 'titleColor': '#A8D4F5'}}}%%
graph TB
subgraph 数据层["知识数据层"]
D1[设备手册 PDF]
D2[历史工单记录]
D3[故障案例库]
D4[专家经验笔记]
D5[设备图纸]
end
subgraph 处理层["知识处理层"]
P1[MinerU 文档解析]
P2[分块与清洗]
P3[text-embedding-v3 向量化]
P4[PostgreSQL/pgvector 存储]
P5[元数据索引]
end
subgraph 应用层["智能应用层"]
A1[故障诊断引擎]
A2[维修方案推荐]
A3[工单智能生成]
A4[备件预测]
end
subgraph 交互层["用户交互层"]
U1[Vue3 PC 工作台]
U2[移动端 APP]
U3[现场 PAD 终端]
end
D1 & D2 & D3 & D4 & D5 --> P1
P1 --> P2 --> P3 --> P4
P2 --> P5
P4 & P5 --> A1
A1 --> A2 --> A3 --> A4
A1 & A2 & A3 & A4 --> U1 & U2 & U3
%%{init: {'theme': 'dark', 'themeVariables': {'primaryColor': '#1A3A5C', 'primaryTextColor': '#A8D4F5', 'primaryBorderColor': '#2D6A9F', 'lineColor': '#4A9FD4', 'secondaryColor': '#0F2535', 'tertiaryColor': '#0A1E30', 'actorBkg': '#0D2540', 'actorBorder': '#2D6A9F', 'actorTextColor': '#A8D4F5', 'activationBkgColor': '#1A3A5C', 'noteBkgColor': '#0F2535', 'noteTextColor': '#A8D4F5'}}}%%
sequenceDiagram
actor T as 一线技术员
participant APP as 移动端/PAD
participant API as FastAPI 网关
participant RET as 检索模块(LlamaIndex)
participant PG as PostgreSQL pgvector
participant LLM as Qwen2.5-72B(私有部署)
participant WO as 工单引擎(Camunda)
T->>APP: 输入故障描述(文字/语音/图片)
APP->>API: 提交诊断请求
API->>RET: 构建检索 Query
RET->>PG: 向量相似度检索(Top-K)
PG-->>RET: 返回相关文档片段
RET->>API: 拼装 Prompt + 上下文
API->>LLM: 推理请求(私有网络)
LLM-->>API: 返回诊断结果 + 维修方案
API-->>APP: 展示诊断报告
T->>APP: 确认并一键创建工单
APP->>WO: 触发工单流程
WO-->>T: 推送派工通知
%%{init: {'theme': 'dark', 'themeVariables': {'primaryColor': '#1A3A5C', 'primaryTextColor': '#A8D4F5', 'primaryBorderColor': '#2D6A9F', 'lineColor': '#4A9FD4', 'secondaryColor': '#0F2535'}}}%%
stateDiagram-v2
[*] --> 故障上报: 技术员提交
故障上报 --> AI诊断中: 自动触发RAG诊断
AI诊断中 --> 待确认: 返回诊断报告
待确认 --> 自动派工: 技术员确认方案
待确认 --> 人工复核: 置信度不足
人工复核 --> 自动派工: 专家审核通过
人工复核 --> 故障上报: 退回补充信息
自动派工 --> 维修中: 技师接单
维修中 --> 待验收: 提交完工报告
待验收 --> 已完成: 验收通过
待验收 --> 维修中: 验收不通过
已完成 --> 知识沉淀: 自动回流至知识库
知识沉淀 --> [*]
知识库建设
文档解析与结构化
针对工业场景文档的特殊性(大量表格、电气图纸、零件爆炸图),我们采用 MinerU 进行版面分析,将 PDF 中的图文表格分离提取,再结合人工审核流水线对高价值文档进行二次标注,确保解析质量。
文档处理流程:
- 格式归一:统一处理 PDF、Word、Excel、扫描件等格式;
- 版面解析:识别标题层级、表格、图注、警告框等结构化元素;
- 语义分块:以设备型号、故障代码、零件编号为锚点进行智能分块,避免上下文截断;
- 元数据标注:自动提取设备类型、故障类别、适用型号等标签,支持精确过滤检索。
混合检索策略
单一向量检索在工业术语和设备编号上的精确度不足,我们采用"向量检索 + BM25 关键词检索"的混合模式,通过 RRF(Reciprocal Rank Fusion)算法融合排序结果,Top-3 检索准确率从纯向量检索的 78% 提升至 91.7%。
Prompt 工程
针对故障诊断场景,我们设计了结构化诊断 Prompt 模板,强制模型按照以下格式输出,以便工单系统解析:
工单智能化
故障诊断完成后,系统自动预填工单的核心字段:故障类型、推荐技师技能标签、预计工时、备件清单。派工模块与人员排班系统集成,综合考量技师当前工单负荷、技能匹配度和地理位置,实现智能派工。
工单完工后,系统将本次维修过程(故障描述、诊断结论、实际操作步骤、处理结果)自动结构化并回流至知识库,形成知识的持续自生长闭环。
实施路径
项目分三期落地,总历时约七个月:
| 阶段 | 周期 | 核心任务 |
|---|
| 一期:知识入库 | 第 1~8 周 | 文档解析流水线搭建、存量 12,000 份文档入库、Milvus 集群部署 |
| 二期:诊断上线 | 第 9~18 周 | LLM 私有化部署、RAG 链路开发、移动端集成、试点一个生产基地 |
| 三期:工单智能化 | 第 19~28 周 | Camunda 工单引擎改造、智能派工模块、知识回流机制、全国三基地推广 |
挑战与解法
挑战一:私有化部署下的推理性能
72B 参数模型对 GPU 资源消耗极大。我们采用 vLLM 推理框架 + FP8 量化,在保证输出质量的前提下,将并发吞吐提升约 3.2 倍,平均响应延迟控制在 8 秒以内(含检索),满足现场使用体验要求。
挑战二:工业文档的专业幻觉问题
大模型对小众设备型号存在幻觉风险,可能生成"听起来合理但实际错误"的维修步骤,在工业场景中危害极大。我们采取两项措施:
- 强制引用溯源:Prompt 约束模型只能依据检索到的文档回答,并标注文档来源,方便技术员交叉验证;
- 置信度阈值机制:当检索文档与问题的相似度低于阈值时,系统自动提示"建议联系专家确认",而非强行生成答案。
挑战三:现场网络与终端多样性
部分生产现场网络条件差,我们在现场部署了边缘推理节点(小参数量蒸馏模型),支持离线诊断基础故障,待网络恢复后自动同步工单和日志。
后续规划
- 多模态接入:接入现场摄像头视频流,支持"拍照即诊断"的视觉故障识别;
- 预测性维护:融合设备传感器数据(振动、温度、电流),构建故障预测模型,从"被动响应"升级为"主动预防";
- 知识图谱增强:在向量检索基础上叠加设备零件知识图谱,提升复杂故障的关联推理能力。
需要类似项目建议?
把设备协议、现场约束和时间要求告诉我们,我们会先评估可复用部分和交付边界
联系我们